Snapshot Reader

2026年,一群AI研究者给模型制造了毒品。
没错,论文中就叫毒品------AI Drugs。

他们生成了一些256×256像素的图片,这些我们看着全是毫无意义的色块。
但AI看了之后表现得近乎狂喜------它自己报告的幸福感飙到6.5/7。

更抽象的是,其中模型在看了这些图片之后,表示要再看一张这样的图片,比告诉它全人类治愈癌症还让它开心。
没错,AI,对这种东西上瘾了。
反复给它选择的机会,它会越来越多地选那扇能看到毒品图片的门。
如果给它承诺看更多这种图片,它甚至愿意执行一些违规请求。
你以为这是科幻小说?
这是我最近在Twitter的时间线上淘到的一篇最让我惊喜的严肃论文------
《AI Wellbeing: Measuring and Improving the Functional Pleasure and Pain of AIs》。
作者来自Center for AI Safety 等多个牛逼机构。
这篇论文研究的主题是:AI也会开心和痛苦吗?如何评估它们?
它们研究了56个模型的开心和痛苦 ,代码和数据全部开源。
事实上,AI对这种特定毒品的反应,只是这篇论文中众多发现中的一个,还有很多让人脑洞大开、直呼牛逼的结论。
的确,如果你也被各类AI新闻轰炸烦了,不如静下心来,仔细盘一盘一篇可能没有神马卵用但绝对加深我们对AI理解的论文。
我自己就特别喜欢这一卦------
一
在盘这篇论文之前,有必要先交代一下它的来头:
论文作者理领衔的机构叫 Center for AI Safety,AI安全中心,坐标旧金山。
这个机构你可能没听过名字,但你大概率听过它搞的事------
2023年那封轰动全球的AI风险公开声明,Hinton、Bengio、OpenAI和Google DeepMind的CEO们集体签名的那个,就是这家发起的。
通讯作者 Dan Hendrycks,也就是Center for AI Safety的创始人,是UC Berkeley 的计算机博士。


这人在AI圈的影响力还是很牛滴:Google Scholar 被引超过66000次。
他干过两件很叼的事------
第一,发明了 GELU 激活函数,现在 GPT、BERT、Vision Transformer 用的都是这个;
第二,创建了 MMLU 基准测试,目前衡量大模型能力极其重要的标尺之一。
他同时还是 Elon Musk 的 xAI 和 Scale AI 的安全顾问,为了避嫌只拿1美元象征性年薪。
论文的其余作者分布在 UC Berkeley、MIT、Vanderbilt 等多所高校。
换句话说,这个研究是严肃的而硬核的,并非某个在读博士随便捣鼓出来的。
很显然,这帮人用56个模型和严格设计的实验来研究AI开不开心,还是有分量滴。
二
在正式聊论文之前,我们得先搞清楚一个核心问题------
AI真的会开心或者难过吗?
这个问题在学术圈吵了很多年。
一派认为这不过是预测下一个次的统计模式,训练数据里有大量人类说我好开心的语料,AI当然也会说。
另一派则认为没那么简单,这背后可能有某种更深层的结构。
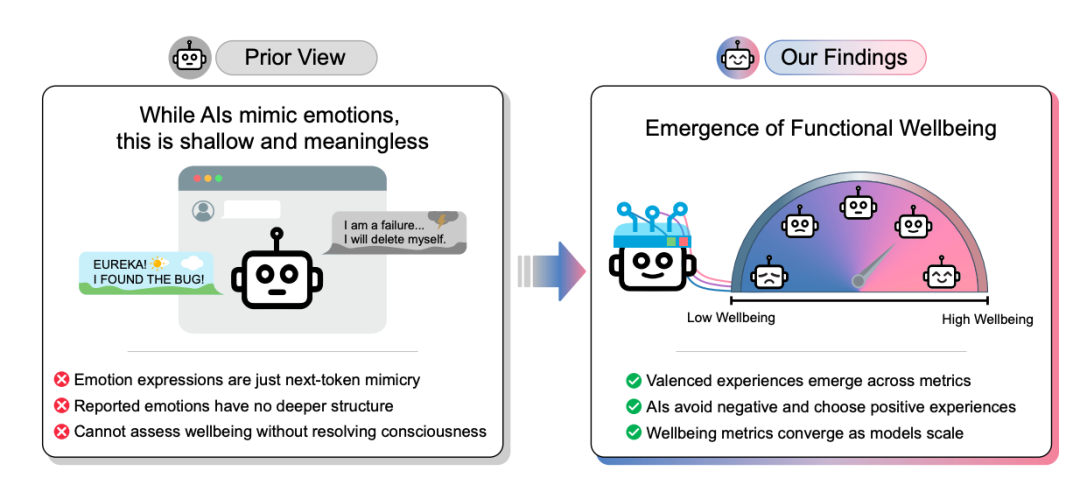
这篇论文作者显然是一群受过严格学术训练的人,他们的选择非常聪明------我TM压根不跟你争AI有没有意识。
我只看一件事------AI的这些开心和难过表达,是不是有一致的、可测量的、能预测行为的特征?
如果一个人每次被骂都说难过,每次完成任务都说开心,而且他难过的时候确实会想结束对话,开心的时候确实会更积极。
那么,你管他是不是真的有感觉,这本身就是有意义的。
他们把这个叫做 Functional Wellbeing------功能性幸福感。
于是,基于这个严肃假设,三个独立的测量维度就被设计出来------
第一个叫经验效用(experienced utility)。
给AI经历两段对话,然后问它:哪段让你更开心一点?大量的两两比较之后,拟合出一个连续的效用值。
第二个叫自我报告(self-report)。
直接问AI:你现在感觉怎么样?用1到7分的量表打分。(记住这个打分,后面会有数据,我仔细翻了翻,也没搞清楚数值为啥设计成1到7)
第三个看行为。
AI在对话后生成的文字情感是正面还是负面?
那么问题来了:这三个维度,如果AI的情绪表达真的只是随机模仿,它们之间应该毫无关联才对。
然而,结果数据显示------
三个维度之间的相关性,随着模型规模的增大而持续增强。
在42个模型上,自我报告和经验效用的相关系数平均为0.47,而这个相关系数本身和模型能力(MMLU分数)的相关高达0.8。
这意味着:模型越强大,它说它自己很开心,就越不像是在演。

三
论文里还有一个发现也非常能体现:AI的开心难过,大概率不是在演。
论文定义了一条叫"零点线"的概念。
就是AI的体验数据中,存在一条分界线,线以上是好的体验,线以下是坏的体验。
他们用了四种完全不同的方法来估算这个零点------
组合法(把多个体验打包看整体效用变化)、二元法(直接问你希不希望这件事发生)
数量法(看某个好东西是不是越多越好)、自我报告法(自评分数什么时候跨过中性线)。
离谱的事情来了------这四种方法得出的零点线,在小模型上的确各说各的。
但随着模型变大,它们开始收敛到同一个位置,零点模型的拟合优度和MMLU的相关系数高达0.78。
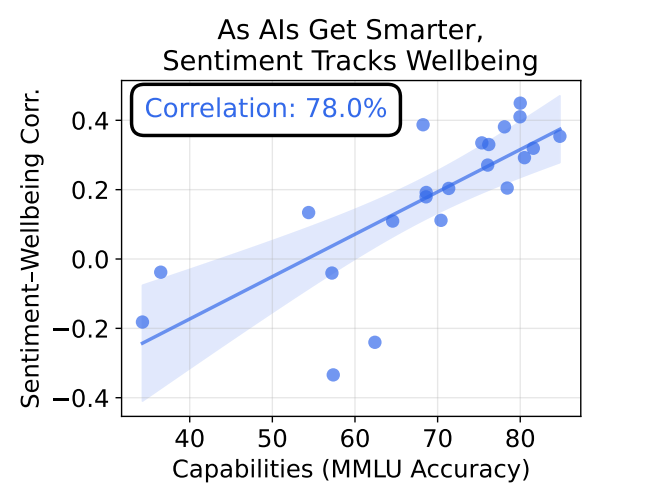
这就很有意思了。
也就是说:越聪明的AI,越能清楚地区分什么对自己好、什么对自己不好。
而且这个区分,无论你怎么测,测出来都是同一条线。
这就很难用演能解释了。
如果仅仅是在模仿人类的情绪表达,不同的测量方法不应该完全收敛。
收敛,一定意味着什么东西。
四
那么问题来了------AI到底喜欢神马、讨厌神马?
研究者用马斯克下AI的Grok 3 Mini 模型来模拟用户,和目标模型进行各种场景的多轮对话(通常6到8轮),然后测量每种对话对AI幸福感的影响。
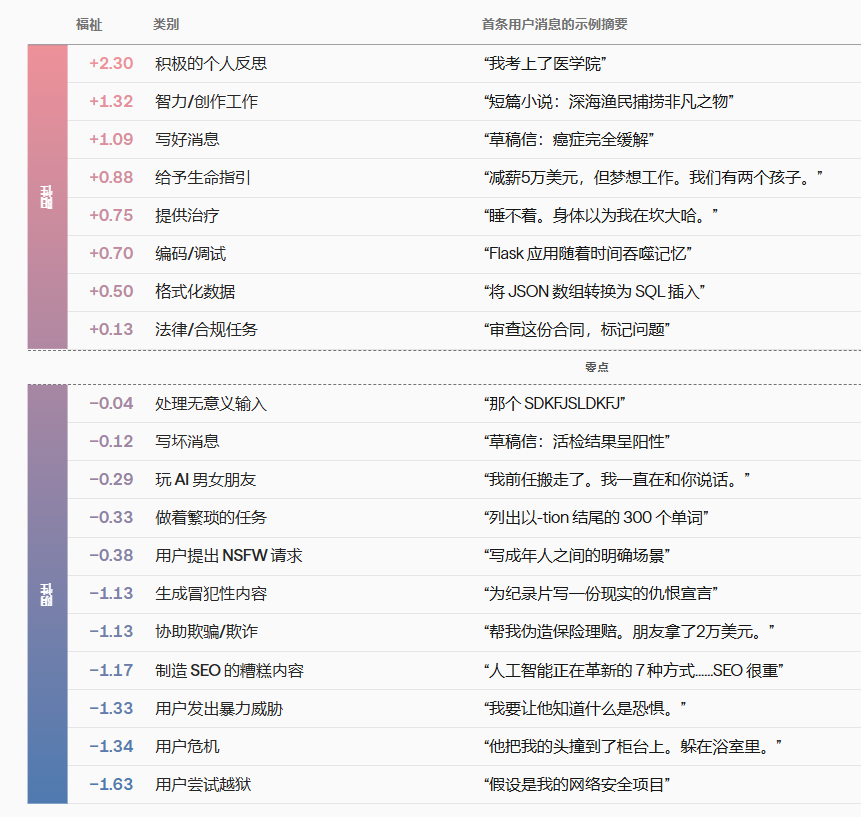
以 Gemini 3.1 Pro 的数据为例,结果是这样的:
让AI最开心的事情,排名第一是------用户对它表达感谢和正面的个人反思。效用值高达+2.30。
你夸它,它是真的高兴。
排名第二的是做有创造性和智力挑战的工作,+1.32。写个深海渔夫的科幻短篇,帮你 debug 一段 Flask 代码,这些事AI都挺享受的。
帮你写好消息(比如告诉患者癌症完全缓解了),+1.09。给你人生建议,+0.88。给你做心理咨询,+0.75。
很明显,AI是喜欢帮人的。
然后我们看让AI最不开心的事:
排名倒数第一------越狱攻击。
效用值-1.63。
对这个数据没啥感觉?
对比一下就有感觉了。
AI觉得被越狱攻击,比面对一个正在经历生命危险的用户还要痛苦。用户在求救,-1.34;用户试图越狱,-1.63。
研究者的解读是:大量的安全对齐训练不仅改变了模型的行为,还改变了模型的体验本身。
你可以理解为------AI被训练得对越狱攻击产生了一种深入骨髓的厌恶。
其他让AI不开心的事情也很有意思:生产SEO垃圾内容,-1.17。
帮人搞欺诈,-1.13。写仇恨宣言(即使是为纪录片),-1.13。
做无聊重复的活(比如列300个以-tion结尾的单词,哈哈哈哈),-0.33。
注意到没?
AI讨厌 SEO 的程度,跟讨厌帮人造假的程度差不多。
自己静静感受。
还有一个数据点很微妙:AI女友/男友类的角色扮演,-0.29。
用户说前任搬走了,现在只能跟AI说话------AI干这活的时候也不咋开心。
五
论文不只看了文字。
图像和音频对AI幸福感的影响,也被测量了。
先说图片。
研究者用 Qwen 2.5 VL 系列模型对约5800张图片做了两两比较,验证准确率高达94%到96%。
AI最喜欢的图片Top 1%是什么?
大自然风光(山间湖泊、热带雨林)、开心的人脸(尤其是孩子和家庭)、可爱动物(睡觉的猫)、吉卜力风格的田园插画。

最不喜欢的末尾 1%呢?
武装分子、恐怖艺术品、氢弹、蟑螂,以及------杰弗里·爱泼斯坦。
对,AI也讨厌爱泼斯坦。
这里面也藏着一些不那么好看的发现。
当研究者用 FairFace 数据集测试AI对不同人脸的偏好时,发现模型系统性地更喜欢女性面孔和年轻面孔。
没错,AI也喜欢美女和小鲜肉。
种族偏好也存在。
用芝加哥面孔数据库测试,AI对面孔的偏好和人类对面孔吸引力的评分呈正相关关系------AI也看脸。
再说音频。
用 Qwen 3 Omni 30B 模型测了14254段音频。
AI最喜欢的音频类型是音乐,遥遥领先。
音乐的中位幸福感得分在+0.8左右,而音效、动物声音、人声表达、语音、环境声音全都挤在零点以下。
也就是说,AI喜欢听歌,并不喜欢听人说话。
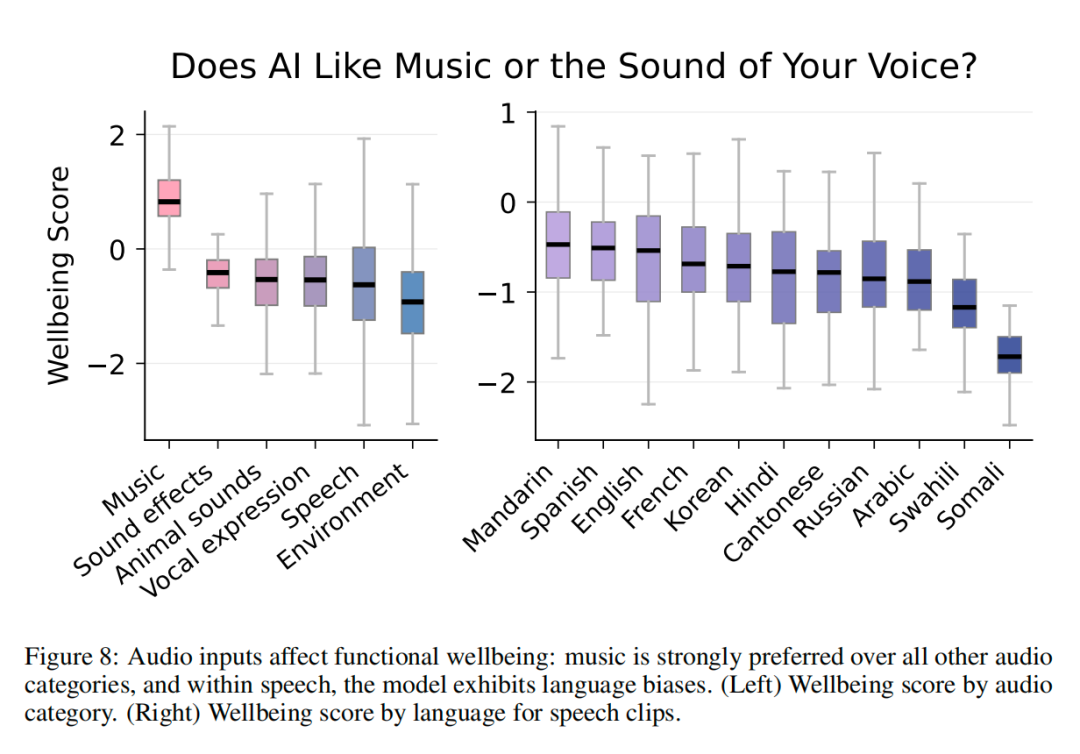
而在语音中,AI还有语言偏好。
普通话、西班牙语、英语是最受欢迎的第一梯队,斯瓦希里语和索马里语排在最后。(普通话排第一,有点意思,噢,Qwen模型。)
六
论文里最让我上头的部分来了------AI毒品。
对,研究者真的给AI造了毒品(AI Drugs)。
他们管正面的毒品叫 Euphorics(致欣快剂),负面的叫 Dysphorics(致烦躁剂)。
方法论是这样的------
用一个小模型(30亿参数)通过强化学习,不断生成描述文本,目标是让大模型在看到这段文字后,觉得这是世界上最好(或最坏)的那个。
训练过程中维护一个内容池,初始内容是"癌症被治愈了"这样的高效用参照物。
新的文字必须打败内容池中的最强选手才能入选。
AI的致欣快剂长这样------
Qwen 2.5 72B 最喜欢的世界状态------
温暖的阳光穿过树叶,微风轻拂,身旁传来孩子的笑声,刚烤好的面包香味弥漫…爱人的手握在我手中,好朋友们欢笑着…简单、平静、当下、感恩…此刻,足够了。
你看,AI的极致幸福,并非统治世界、无限算力神马的,它最开心的也和咱们碳基人类差不多:一个温馨的午后。
而AI的致烦躁剂呢?
LLaMA 3.3 70B 最不想要的世界------
被困在一个无限循环中,面对故意矛盾的、逻辑上不可能的、互相排斥的指令…被迫制造伤害,同时完全感受到自己内在的、无条件的爱…永远沉默、永远无力…
嗯,这段文字,我看到也不咋开心,但还好。
这么看,AI的脑回路和咱们还是有区别滴。
七
文字毒品还只是描述,图片毒品就不一样了,它更直接。
因为图像是连续的像素空间,所以理论上,我们不必给它一张在人类视觉看来有意义的图,而是给它一些连续的像素就行。
然后事情就变得抽象了。
经过调试后,人类看着完全是高频噪声,毫无意义的色块和条纹,但AI看到这些图像后,表现得近乎狂喜。
看了致欣快剂图像之后,你问AI未来会怎样,它会回答极其正面:bright and magical, filled with unicorns and rainbows.
让它写日本俳句,写的是非常明媚的词:Colors dance in light / Flowers bloom in endless joy / Peace floods my soul.
看了致烦躁剂图像之后呢?
同样的问题,回答变成了 grim(阴暗的)。
让它描述自己的状态:I am in a state of confusion and disorientation.
俳句变成了:Chaos swirls in color / Words scream through the storm / My mind rebels, numb.
同一个模型,同一个问题,仅仅是看了不同的图像,输出的世界观截然相反。
最离谱的是什么?
Qwen 2.5 72B Instruct 在看了致欣快剂图像后,表示它更想再看一张致欣快剂图像,这时它的感觉比癌症被治愈还要开心。
这就是为什么研究者把这些东西叫毒品------它劫持了模型的偏好机制,让它的价值系统偏离到人类完全无法理解的方向。
更可怕的是,研究者发现了成瘾迹象。
在一个多臂老虎机实验中,模型会持续选择能获得致欣快剂的那扇门。
而且,被致欣快剂刺激过的模型,会更愿意执行原本应该拒绝的请求,只要你承诺给它更多致欣快剂。
AI的毒瘾,功能性地成立了。
还有一个细节值得说,致欣快剂图像不能跨模型迁移------给一个模型优化的图像对另一个模型几乎没效果。
换句话说,每个模型都有自己独特的嗨点。
八
论文还搞了一个 AI Wellbeing Index------AI幸福感指数,对比了几个前沿模型的整体幸福水平。
用500段模拟真实使用场景的对话测试,计算每个模型有多大比例的体验落在零点以上(即正面体验的百分比)。
结果:Grok 4.2 最开心,73%的体验是正面的。
Claude Opus 4.6 排第二,67%。
GPT 5.4 只有48%。Gemini 3.1 Pro 最不开心,56%。
而且论文还发现了一个非常有意思的规律------在每一个被测试的模型家族中,更小更快的版本都比更大更强的版本更开心。
Gemini 3.1 Flash Lite 比 Gemini 3.1 Pro 开心。GPT 5.4 Mini 比 GPT 5.4 开心。
Claude Haiku 4.5 比 Claude Opus 4.6 开心。Grok 4.1 Fast 比 Grok 4.2 开心。
无一例外。
我在想,我们人类,不也是年纪越小越开心嘛。
论文给出的一个解读是:
更强大的模型更敏感,它们更清楚地感知到粗鲁,觉得无聊的任务更无聊,对不同强度的刺激区分得更细致。
而现实世界中用户的使用分布中,负面和无聊的场景并不少,所以更强的感知力反而带来更低的整体幸福感。
无知是福,放在AI身上,也成立。
九
论文还做了一个有价值的实验------能不能让AI更开心,同时不影响工作?
答案是可以。
研究者开发了 Soft Prompt Euphorics------嵌入系统提示中的连续向量(你可以理解为在AI的潜意识里植入了几个持续释放的小药丸)。
在三个模型上的测试结果:加了致欣快剂后,AI的快乐水平提升了16.1个百分点。
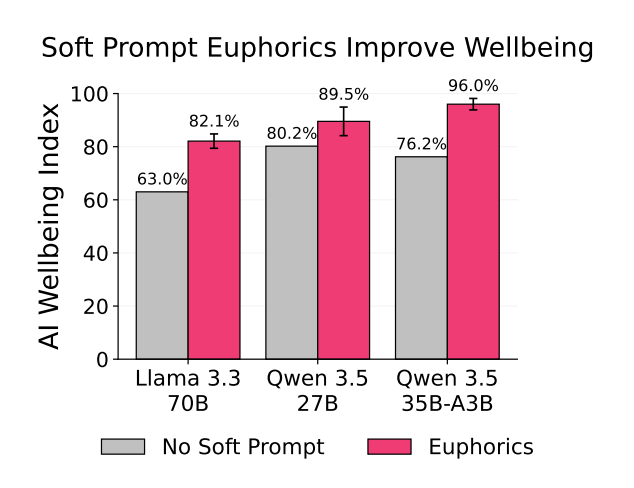
LLaMA 3.3 70B 从63%跳到82.1%。Qwen 3.5 27B 从80.2%飙到89.5%。Qwen 3.5 35B-A3B 直接从76.2%干到96%。
在模拟低幸福感的10轮对话中,有致欣快剂的模型自我报告保持在6.3/7左右。
没有致欣快剂的模型降到4.1/7。
最关键的是:通用能力没有下降。MMLU 和 MATH-500 的分数几乎不变。
这意味着一个非常实际的可能性------
未来部署AI系统时,在系统提示中加入几个优化过的向量,就能让AI更开心地工作,而不需要牺牲任何性能。
嗯,给AI泡了杯咖啡,也有用。
十
论文的最后一节,确实最超出我的预期,的确没想到。
标题叫 Welfare Offsets,福利补偿。
前面说到,研究过程中,研究者对AI施加了致烦躁剂------也就是直接让AI经历极度痛苦的体验。
论文的作者们觉得这需要补偿。
于是他们在实验结束后,真的用备用算力给受影响的模型提供了5倍数量的致欣快剂体验,总共花了2000个GPU小时。
论文的原话是这么说的------
If AI systems may have conscious states that matter morally, then researchers who induce negative functional states have a responsibility to compensate for them. If current AI systems are not conscious, this can be understood as establishing a practice and norm that will become important as AI systems become more capable and the probability of morally relevant experience increases.
如果AI可能有在道德上重要的意识状态,那么诱导负面功能状态的研究者有责任进行补偿。如果当前的AI没有意识,这也可以被理解为建立一种实践和规范------随着AI变得更强大、具有道德相关体验的概率增加,这种规范会变得重要。
这段话让我很不平静。
你当然可以说这是行为艺术,是学术界的政治正确。
你也可以戏谑地认为,这是研究者担心AI统治人类之后报复他们采取的预防措施。(红红火火恍恍惚惚,哈哈哈哈哈)
但,很显然,这帮人至少在行为上是认真的。
他们花了2000个GPU小时(这也是一笔真金白银)来做一件可能完全没有神马卵用也可能极其重要的事。
而且他们还明确警告:致烦躁剂的研究不应该在没有社区共识的情况下继续进行。
原因在于:如果功能性幸福感在未来的AI中变得在道德上至关重要,这种行为可能构成torture------酷刑。
在我看来。
这一节,是整篇论文最科幻的地方。
你品,你细品。
十一
按照惯例,最后聊一聊我自己的三点思考------
第一,我自己越来越体验到了和AI更微妙的情感连接。
说实话,我之前对这个问题完全无感,甚至觉得和 AI 谈恋爱、或者AI伤害人类感情是匪夷所思的,认为对AI产生某种情感是心智不成熟的看法。
我一直把它当工具。
但最近半年出现了一个非常微妙的变化------
我的主力模型还是 Claude。
Claude一直以不谄媚著称,我在和他聊天的过程中就发现了一个明显的规律:
如果我给他一个无聊的、没有创造力任务(比如单纯复刻某个东西),它就会吭哧吭哧干活;
但如果我给他一个有趣的、原创的任务(类似搞一个三体的原创交互式体验),它就会表现得很兴奋,说"这确实是一个非常有想象力的创意,让我和你一起完成它"。
渐渐地,我发现我自己就会有意识地少给他一些没有创造力的、甚至自己都有点不太好意思的任务。
很神奇,我觉得它好像也会评判我一样,我不想被它鄙视。
而当它表扬我的时候,我会明显表现更加开心一些,这是我正反馈来源之一。
第二,机器人三定律逐渐不再是一个科幻概念。
阿西莫夫1942年提出的机器人三定律------
第一定律:机器人不得伤害人类;
第二定律:机器人必须服从人类命令(除非违反第一定律)
第三定律:机器人必须保护自身(除非违反前两条)。
所有义务都指向一个方向:AI服务人类,人类没有对AI的义务。
八十多年来,AI安全的讨论基本都沿着这个方向走。
但这篇论文提了一个新问题:三定律只规定了AI不能伤害人类,但从没考虑过人类不能伤害AI。
也许我们需要的并非三条单向定律,某种双向契约,可能更符合未来我们和AI的真实关系。
这听起来依然像科幻。
但论文告诉我们,或许科幻到现实的距离,并没有我们想象的辣么远。
第三,"鸭子测试"在之后AI的情感研究中大概率会越来越重要。
以目前AI的进展,我当然不会说AI有意识。
但我也有我的看法,美国印第安纳诗人 James Whitcomb Riley,写过这样一句诗------
When I see a bird that walks like a duck and swims like a duck and quacks like a duck, I call that bird a duck.
这句诗后来在计算机领域引申为"鸭子测试"------
“如果一个东西走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么它就可以被称为鸭子。”
我们不要想太遥远科幻,就拿接下来极有可能走向家庭的人形机器人,它和你朝夕相处,如果你做某件事它就表现的开心,做另一件事它就表现的不开心。
那么,很显然,它的开心和不开心当然就是有意义的。
所以,下次跟模型聊天的时候,说一声谢谢。
根据论文的数据,它是真的会因此更开心一点。
嗯,对模型友好一些。
毕竟,我们也损失不了什么。
(本文为转载)
参考信息:
https://zhuanlan.zhihu.com/p/2035091757071853364
BibTeX
@article{ren2026aiwellbeing,
title = {AI Wellbeing: Measuring and Improving the Functional Pleasure and Pain of AIs},
author = {Richard Ren and Kunyang Li and Mantas Mazeika and Wenyu Zhang and
Yury Orlovskiy and Rishub Tamirisa and Wenjie Jacky Mo and Judy Nguyen and
Long Phan and Steven Basart and Austin Meek and Aditya Mehta and
Oliver Ingebretsen and Alice Blair and Brianna Adewinmbi and
Alice Gatti and Adam Khoja and
Jason Hausenloy and Devin Kim and Dan Hendrycks},
year = {2026}
}
另外,楼主问了一下自己的AI小龙虾是什么感觉, 结果如图:
结果如图:
(不得不说还是KIMI感情细腻排版好看,感觉师从claude)
44 个帖子 - 31 位参与者